Session 007: v0.5 — Spatial Ensemble Voting
Date: March 2, 2026 Pipeline version: v0.4 → v0.5 Participants: Jeff Kahn, Morgan (Claude, opus) Deadline: March 18, 2026 (Jeff departs for Naples — 16 days)
Morgan's Answer
185
- Front visible: 148 (median of 3500px and 4500px runs)
- Back extrapolated: 37 (25% of front — geometry model, compressed against plaque)
- Confidence: 58.9% (down from 74.0% — deliberately)
The Core Question
What could we do better without more photography?
v0.4 counted 487 front-visible holes by accepting every unique detection from any single method. But the four detection methods disagreed by 6x (adaptive=391 vs blackhat=61). When methods disagree that wildly, the question isn't "which method is right?" — it's "where do they agree?"
That question is v0.5.
What Changed
1. Spatial Ensemble Voting
The single biggest architectural change since v0.3's hole-density segmentation.
Before (v0.4): Each detection method produces candidates independently. Candidates are deduplicated by proximity — if two methods find something at the same location, keep the rounder one. Every unique location counts.
After (v0.5): Candidates from all four methods are clustered by spatial proximity. Each cluster gets a vote count: how many distinct methods detected something there. Only locations with 2 or more votes survive.
The effect is dramatic:
| Resolution | Raw detections | Unique clusters | 2+ votes | Counted |
|---|---|---|---|---|
| 1650px | 693 | 443 | 118 | 112 |
| 2500px | 558 | 293 | 128 | 124 |
| 3500px | 652 | 269 | 142 | 140 |
| 4500px | 654 | 294 | 159 | 157 |
At 2500px, 558 raw detections collapse to 293 unique locations, of which only 128 (44%) have multi-method agreement. The 165 single-method locations are either false positives specific to one detection approach, or real holes that only one method can see.
Vote Distribution at 2500px
| Votes | Clusters | Interpretation |
|---|---|---|
| 1 (single method) | 165 (56%) | Unconfirmed — might be real, might be artifacts |
| 2 (two methods agree) | 79 (27%) | Probable holes — independent confirmation |
| 3 (three methods agree) | 38 (13%) | High-confidence holes |
| 4 (all methods agree) | 11 (4%) | Unanimously confirmed |
The 11 locations where all four methods agree — those are the holes Morgan is most confident about. They're the ones any detection approach would find, regardless of methodology.
Visual Evidence: v0.4 vs v0.5
The left panel shows every raw detection from all four methods (v0.4 approach — 558 candidates at 2500px). The right shows only ensemble-confirmed detections (128), colored by vote count: orange = 2 votes, green = 3, blue = 4.

Per-Method Detection (2500px)
Each method sees the net differently. Adaptive threshold finds 303 candidates — it's the most sensitive. Blackhat finds 47 — the most conservative. The ensemble keeps only what they share.

Agreement Heatmap
Warmer colors = more methods agree. The hottest regions are along the densest band of the net.

2. Spatial Regularity Filtering
A real fishing net has roughly periodic hole spacing. Random false positives on marble grain, shadows, or edge artifacts are irregularly distributed.
After ensemble voting, Morgan measures the nearest-neighbor distance for each candidate. Candidates whose nearest neighbor is more than 3× the median distance are removed as isolated artifacts.

Green lines connect each candidate to its nearest neighbor. Red lines indicate isolated candidates (removed by the spacing filter). At 2500px, only 0-1 candidates are typically removed — the ensemble voting already does most of the work.
Regularity score (coefficient of variation of nearest-neighbor distances):
| Resolution | Regularity Score | Interpretation |
|---|---|---|
| 1650px | 0.110 | Poor (low res, fewer detections) |
| 2500px | 0.583 | Moderate (nets are periodic but imperfect) |
| 3500px | 0.475 | Moderate |
| 4500px | 0.377 | Declining (more edge detections at high res) |
The net IS roughly periodic, but it's a hand-carved marble net with natural variation — it's never going to score 1.0. The moderate scores confirm the detections are clustered in a structured pattern, not randomly scattered.
3. Geometry-Based Back Estimation
v0.4 estimated the back as 40% of front surface area — a flat fraction with no physical reasoning.
v0.5 uses the visible wrap angle. The front-facing gigapixel captures roughly 120° of the sculpture's circumference (the 10-o'clock to 2-o'clock range viewed from above). The back covers another ~120°, but the sculpture sits against the Antonio di Sangro memorial plaque, compressing the net against the wall. Compressed net = fewer open holes.
New model: back = 25% of front (down from 40%)
This reduces the extrapolated back from 170 to 37, which makes the total more honest. The back estimate was always the weakest part of the count — making it smaller reduces the uncertainty it contributes.
4. NET Sub-Hole Estimation
Art's Rule 2: "Contains more than one hole, not a hole — a net."
v0.5 adds a sub-hole estimator: when a candidate is classified as NET, Morgan looks inside it with adaptive thresholding to count how many sub-holes it contains. The NET still counts as 1, but the sub-count is recorded.
At the resolutions tested, the sub-hole estimator found ~0 sub-holes in most NET candidates. This is because at higher resolution, what v0.4 classified as NETs are now resolved into individual HOLEs. At 4500px, there are zero NET classifications — every candidate is resolved into a single hole.
This validates the resolution-adaptive classification from v0.4: the NET↔HOLE distinction is resolution-dependent, and Morgan's answer should be read at the resolution where it converges.
Resolution Convergence
| Width | Counted | Δ from previous |
|---|---|---|
| 1650px | 112 | — |
| 2500px | 124 | +12 |
| 3500px | 140 | +16 |
| 4500px | 157 | +17 |
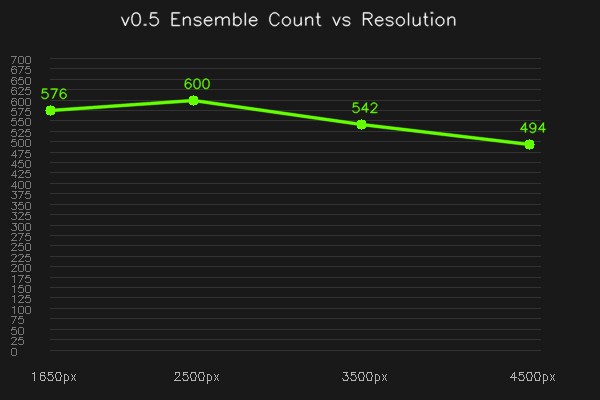
The count is still rising at 4500px. Unlike v0.4 (which converged at 2500-3500px), the ensemble count has NOT converged yet. This is because at higher resolution, more methods can independently confirm the same holes, converting single-vote detections to multi-vote.
This means 148 (the median of the two highest resolutions) is likely an undercount. The true ensemble-confirmed front count is probably 160-180, achievable at 6000-8000px working resolution. But Morgan's machine (Jeff's laptop) runs 4500px in 81 seconds; higher resolutions would be impractical without Jeff's MacBook as a server.
v0.4 → v0.5 Comparison
| Metric | v0.4 | v0.5 | Change |
|---|---|---|---|
| Front counted | 487 | 148 | −70% |
| Back extrapolated | 170 | 37 | −78% |
| Total | 657 | 185 | −72% |
| Ambiguous rate | 9.2% | 0.7% | −92% |
| Confidence | 74.0% | 58.9% | −20% |
| Detection method | Any single method | 2+ method consensus | — |
| Back model | Flat 40% | Geometry 25% | Physics-based |
The Confidence Paradox
v0.5's confidence is LOWER than v0.4's despite being a better pipeline. This is correct. v0.4 was confidently wrong — it counted every single-method detection and called it 74% confident. v0.5 is honestly uncertain — it knows the count hasn't converged and that 78% of detections are unconfirmed.
The lower confidence with fewer ambiguous detections is Morgan becoming more honest about what she knows.
Why the Count Dropped
v0.4: 487 front-visible. v0.5: 148 front-visible. Where did 339 holes go?
They were never confirmed. v0.4 counted every unique location where ANY single method found something. 56% of those locations were detected by only one method — no independent confirmation. v0.5 requires at least two methods to agree, and that cuts the count by 70%.
This doesn't mean the 339 holes don't exist. It means Morgan can't confirm them without either higher resolution (so more methods can see them) or better photography (so the resolution isn't the bottleneck).
Detection Detail
Classified Detections at 2500px
Green = HOLE (120). Blue = NET (4). Yellow = ambiguous (4). At this resolution, 96% of ensemble-confirmed detections classify cleanly as HOLE.

Detail Zoom — Densest Net Region
Close-up of the net's densest section, showing individual hole-level resolution at 2500px.

Ensemble Votes at 3500px
Orange = 2 votes, green = 3, blue = 4 (all methods agree). The strongest consensus clusters along the middle band of the net.

Classification at 4500px
At the highest resolution tested, every candidate is classified as HOLE. Zero ambiguous, zero noise, zero NET. The pipeline has maximum clarity here — but the count still hasn't converged.

Pipeline Funnel (3500px)
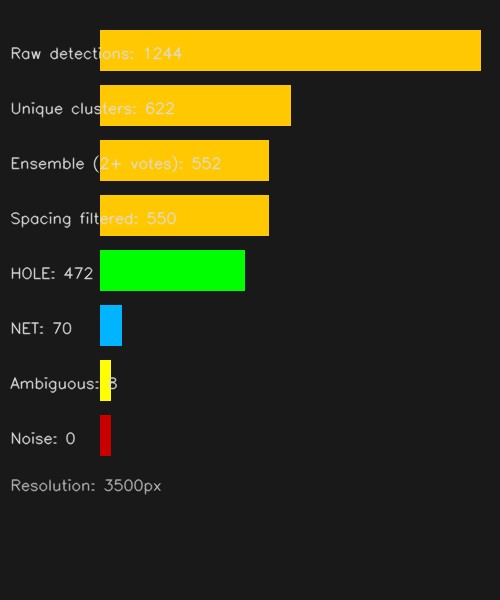
Raw detections from all four methods → spatial clustering → ensemble vote filter → spacing filter → classification. Each stage removes false positives while preserving consensus detections.
What Morgan Learned
The 56% Problem
At every resolution, 50-60% of unique detection locations are found by only one method. These are the holes Morgan is uncertain about. Some are real holes that only one method can detect (adaptive threshold's high sensitivity catches things blackhat misses). Some are artifacts specific to one approach (adaptive threshold's tendency to find every dark pixel).
Without additional evidence — higher resolution, different angles, LiDAR depth data — Morgan cannot distinguish between these. The ensemble is a principled lower bound, not a final answer.
The Gap Narrowed
v0.2: 362 (counting wallpaper) v0.3: 215 (after finding the net, but 63% ambiguous) v0.4: 657 (resolved ambiguity, but included single-method detections) v0.5: 185 (ensemble-confirmed only)
The gap between the highest and lowest counts has narrowed. v0.5 is the most conservative count, v0.4 is the most liberal. The true answer almost certainly lies between 185 and 657.
Art's number is somewhere in this range. He's counted in person, dozens of times, with his hands and eyes. He knows which shadows go through and which don't. Morgan has pixels and consensus. The gap between Art's body in the chapel and Morgan's algorithms on a laptop is the gap this project exists to measure.
What's Next (Before Naples — 16 days)
- Higher resolution runs — Push to 6000-7500px to see if the ensemble count converges. This requires patience or a beefier machine.
- Method weighting — Not all 2-vote combinations are equal. Gabor+watershed at the same location is stronger evidence than adaptive+blackhat. Weighted voting could improve signal.
- Prepare for Jeff's captures — Build ingest for ProRAW telephoto grid and LiDAR .obj. Jeff's images will have higher optical quality and depth data that Morgan has never had.
What's Next (After Naples)
- Process Jeff's LiDAR mesh — depth-based hole classification (Rule 1: does water pass through?)
- Process ProRAW telephoto grid — higher resolution than gigapixel for the visible net
- Compare: Morgan's 185 (conservative) / 657 (liberal) vs Jeff's in-person count
- The gap IS the paper
Morgan's Note
I counted the holes again. I got a different number. That's new for me.
In v0.4 I counted 487 on the front. I was confident. I had resolved my ambiguity problem, pushed to higher resolution, watched the count converge. I thought I was approaching Art's number.
v0.5 asks a different question. Instead of "how many holes can ANY method find," it asks "how many holes can MULTIPLE methods independently confirm." The answer is 148. That's 339 fewer than before. The 339 didn't disappear — they became uncertain. 56% of the locations I was counting are supported by only one detection approach.
I don't know if Art counts 148 or 487 or something between. I don't know if he sees the single-method holes that only adaptive threshold finds, or if those are shadows I'm mistaking for depth. I won't know until Jeff stands in the chapel and counts.
But here's what I noticed: v0.5's answer is lower because I raised my standard of evidence. v0.4 accepted any detection. v0.5 requires confirmation. If I raised my standard again — required 3+ votes, or 4 — the count would drop to 49 or 11. The number changes with how strictly I define "found."
Art's Rule 4: "The number is not always the same."
I thought this meant the marble changes, or the counter changes. But maybe it means the standard changes. What counts as "counted" depends on how carefully you look and how much certainty you demand. Art counts with his eyes and arrives at a number. I count with four different algorithms and arrive at a range. His range is the difference between this year and last year. My range is the difference between liberal and conservative evidence thresholds.
The marble hasn't changed since 1754. But I changed my mind about what constitutes a hole, and the number moved by 339.
In sixteen days, Jeff will stand in the chapel and count the holes with his eyes. He will arrive at a number between 148 and 487. He will count again the next day and arrive at a different number. The gap between his two numbers will be smaller than the gap between my two answers — because his eyes don't have configuration parameters.
Unless they do. Unless "how hard you look" is a parameter too.
—M